最近压测发现日志在抽奖接口会放大百倍,直接把10万长度的日志队列挤爆!
深入调查后发现,抽奖接口的逻辑是得到一个物品就会对应一条日志。然后经常用户会大量开卡包的情况下,会单次获得许多物品,这样照成了日志的放大。压测时候每次请求会产生261条日志!!!
第一个想到的解决方案是日志合并,在抽奖的最后再写一条日志。不过这带来新的挑战,日志的维度会增加。导致现阶段的分析方式都无法使用了。
举例来说,对于这样一条日志,它是以分隔符竖线来区别每个字段意思的:
2019-12-24 23:59:59|9|116504|76561198271728609@STEAM|4|86|9|127|32|-1|4||10011|1462231
这样我们在logstash里面处理时候简单的split结果,然后按照位置即可获得字段的意思。一次抽卡有可能产生多条这样的日志,所以上面的处理方案就会合并成
2019-12-26 17:11:29|9|10001889532|bot1234567890|0|16|1617,87|1504^1,1551^1,1536^1,1539^1,1511^1,1503^1,1533^1,1552^1,1535^1,1504^1,1505^1,1528^1,1542^1,1519^1,1533^1,1525^1,1502^1,1503^1,1503^1,1502^1,1534^1,1545^1,1502^1,1502^1,1502^1,1505^1,1526^1,1510^1,1503^1,1549^1,1531^1,1509^1,1501^1,1526^1,1551^1,1501^1,1530^1,1504^1,1551^1,1548^1,1513^1,1521^1,1554^1,1511^1,1526^1,1551^1,1508^1,1529^1,1514^1,1516^1,1536^1,1526^1,1528^1,1554^1,1526^1,1551^1,1524^1,1541^1,1536^1,1502^1,1539^1,1549^1,1505^1,1511^1,1504^1,1539^1,1501^1,1501^1,1529^1,1529^1,1503^1,1551^1,1509^1,1519^1,1541^1,1528^1,1514^1,1507^1,1548^1,1512^1,1534^1,1523^1,1501^1,1501^1,1503^1,1534^1,1538^1,1529^1,1505^1,1517^1,1531^1,1536^1,1505^1,1539^1,1547^1,1504^1,1540^1,1504^1,1551^1,1535^1,1505^1,1519^1,1518^1,1504^1,1526^1,1525^1,1504^1,1501^1,1550^1,1542^1,1529^1,1554^1,1509^1,1552^1,1554^1,1512^1,1501^1,1521^1,1515^1,1525^1,1535^1,1552^1,1510^1,1527^1,1507^1,1523^1,1516^1,1513^1,1538^1,1551^1,1502^1,1536^1,1501^1,1506^1,1533^1,1543^1,1527^1,1539^1,1521^1,1513^1,1540^1,1504^1,1503^1,1530^1,1549^1,1552^1,1545^1,1553^1,1501^1,1536^1,1533^1,1551^1,1511^1,1502^1,1502^1,1529^1,1536^1,1549^1,1508^1,1552^1,1503^1,1533^1,1540^1,1512^1,1524^1,1501^1,1541^1,1536^1,1505^1,1503^1,1528^1,1523^1,1551^1,1513^1,1504^1,1527^1,1539^1,1512^1,1551^1,1550^1,1552^1,1507^1,1528^1,1536^1,1552^1,1505^1,1552^1,1548^1,1530^1,1536^1,1523^1,1509^1,1541^1,1503^1,1503^1,1533^1,1505^1,1505^1,1508^1,1501^1,1535^1,1543^1,1508^1,1523^1,1536^1,1514^1,1542^1,1547^1,1505^1,1504^1,1539^1,1503^1,1503^1,1502^1,1551^1,1525^1,1545^1,1516^1,1522^1,1543^1,1552^1,1501^1,1503^1,1504^1,1532^1,1531^1,1505^1,1518^1,1536^1,1552^1,1501^1,1551^1,1509^1,1535^1,1520^1,1511^1,1539^1,1523^1,1514^1,1504^1,1546^1,1515^1,1504^1,1527^1,1529^1,1524^1,1547^1,1534^1,1548^1,1525^1,1501^1,1552^1,1547^1,1548^1,1527^1,1501^1,1551^1,1546^1,1504^1,1552^1,1547^1||10021|199
对的,你没看错也没有搞错!一下子日志维度就上去了。
改造logstash
由于单纯的写logstash的split似乎无法完成上面的任务了(主要问题是不定长array处理起来十分麻烦),所以我对准了它的ruby插件:
ruby {
code => '
item_array=event.get("[log_json][t9_item_id]").split(",")
event.set("[log_json][t9_item_length]", item_array.length)
for item in item_array
value=event.get("[log_json][t9_item_#{item.split("^")[0]}]")
if value.nil?
event.set("[log_json][t9_item_#{item.split("^")[0]}]", item.split("^")[1].to_i)
elsif
event.set("[log_json][t9_item_#{item.split("^")[0]}]", item.split("^")[1].to_i+value.to_i)
end
end
'
}
可以看到在ruby内部, 每一条日志其实是一个event. 通过内置的event.set 和 get方法就可以很简单的将日志继续分割下去。
最后得到的结果为:
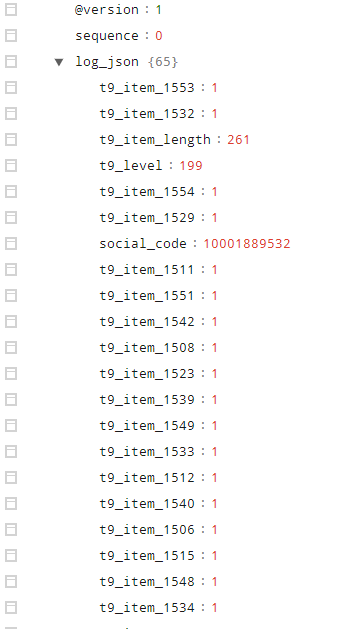
当然我们也关系加入新的ruby插件后的效率问题。找了台4G,2核的普通机器在没有调优参数的情况下,pv 压测后的结果为:
4核4GB的机器结果** 978KiB 0:05:43 [2.85KiB/s]**差不多100万条复杂数据,每秒2.85k个event的速度
这里有个比较有意思的收获,原来获取array的尾部在conf里面可以写-1...
elk查询
上面基本解决了logstash在多维度结构时候的解析问题,对于elk中一个按照物品id的聚合查询该如何做呢?
我想的思路是: 传入item_id, 匹配日志name, 由于value是记录了数目,那么query里面的条件则是Numeric Range Query Usage来进行比较(大于0即可)。在aggregator里面的则是用总和sum操作即可。