首先祭出一般的复杂操作优化方案

-
历史价格不需要拿出全部数据。看现在这部分大小不大都在1KB左右,但是由于时间长了某些物品的价格数量比较多导致list会比较长。

-
部分玩家的事务队列是否可能出现堆积,然后队列过长?
-
寄售队列查了日志访问人数不多,将来可以考虑寄售过期之类,防止过长。
-
可以定一个大概取间让队列尽量控制在5000以内,排查下用队列比较多的地方,比如排行榜之类。
-
LDR:0:1 作为排行榜也是最热的key,需要控制大小和长度。

-
建议有expire的地方,如果觉得会有大量数据的前提下,都加一个随机数.像下面这种循环内设置统一过期时间的做法就有点危险

-
保持主redis只放和用户相关的重要数据,周围数据都可以放在另外的redis中,需要梳理业务。
-
对于stackexchage的连接做保护
-
每日凌晨发现有集中的内存释放,并且空间还比较大.
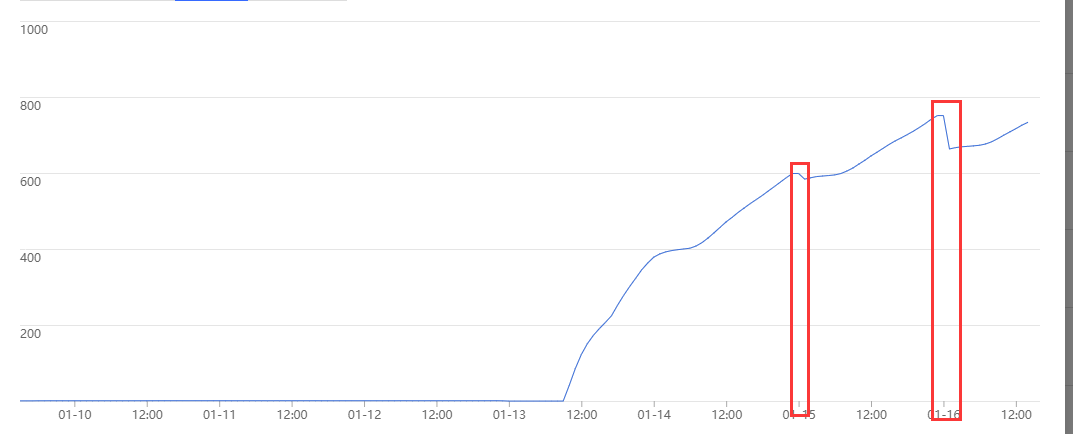
分析完业务后发现是排行榜集中时间过期,没有做随机延迟。
排行榜大的原因是没有限制数目导致的,并且还有一个安全隐患就是设置数据和expire是两条语句,有可能导致内存泄露。
public static async Task RenewDailyStar(RaidType type, int relatedID, RaidDailyStar star)
{
var oldStar = RedisValue.Null;
var key = GetDailyStarKey(type, relatedID);
// 防止集中过期
var expRandom = TimeSpan.FromDays(offlineExpireDay).Add(TimeSpan.FromSeconds(MathHelper.GetRandom(0, 600)));
try
{
// fetch last daily star
var cacheStar = SerializationHelper.Serialize(star);
// getset is atomic
oldStar = await RedisServer.Instance().DB(dailyStarDB).StringGetSetAsync(key, cacheStar);
if (oldStar != RedisValue.Null)
{
// compare with oldstar
if (oldStar.Get<RaidDailyStar>().GetFinalScore() > star.GetFinalScore())
await RedisServer.Instance().DB(dailyStarDB).StringSetAsync(key, oldStar, expRandom);
}
}
catch (Exception ex)
{
LogHelper.WriteErrorLog(string.Format("{0} | {1}", star.GetFinalScore(), ex.Message));
// 滚回操作
if (oldStar != RedisValue.Null)
await RedisServer.Instance().DB(dailyStarDB).StringSetAsync(key, oldStar, expRandom);
}
}
- 这里是个批处理,而不是pipeline,由于取了1000位排行榜玩家数据,所以很可能这边会相当耗时。

在最外层的调用地方还有一个for循环加持放大

分析腾讯的监控看那个面板可以看到,每个一个小时延迟和读数目有个尖峰。应该就是这个原因导致的。
