去年年底封测的第一个晚上,晚高峰时候,本来一切平和。但是在毫无征兆的情况下,突然线上redis断了。检查了机房连接没有问题,并且线上10多个实例,只有一台机器的redis断掉了。十分诡异!排查了一个小时没有任何结果,此次问题造成了大概800人回档。对于当时近万人的同时在线,还算损失比较小。
这个错误在以前的测试,包括压测过程中都没有出现过。并且steam服务器跑了也将近半年没有问题。但当时简单修复相关业务逻辑后,这个错误在封测期间再也没有问题了。所以又搁置了起来。
不过封测停止后,这个问题突然在steam服务器也多了起来。辛亏的是当时做了一个保护措施(一旦发现redis连接断掉就立马重连)。所以还算安稳度过到现在。
如何稳定复现这个问题?
现在摆在手上的日志只有failed to write时候一定会断线,于是找到我们使用的这个第三方客户端源码研读起来:

这就是抛错的地方,的确是连接问题。但是什么条件会抛呢?由于源码实在复杂,所以这部分并没有继续下去。
继续深挖
由于最近几乎每天redis都会自动断掉然后重连,于是决定直接monitor现场。这个命令的作用就是看redis当时在处理什么命令。具体可以参考官方文档。结果发现监控不多久就出现了如下错误:

然后同样也是连接断掉了。当然redis自己还是稳定运行的。在网上查了下相关问题,很多人给的答案有点让人捉摸不透:
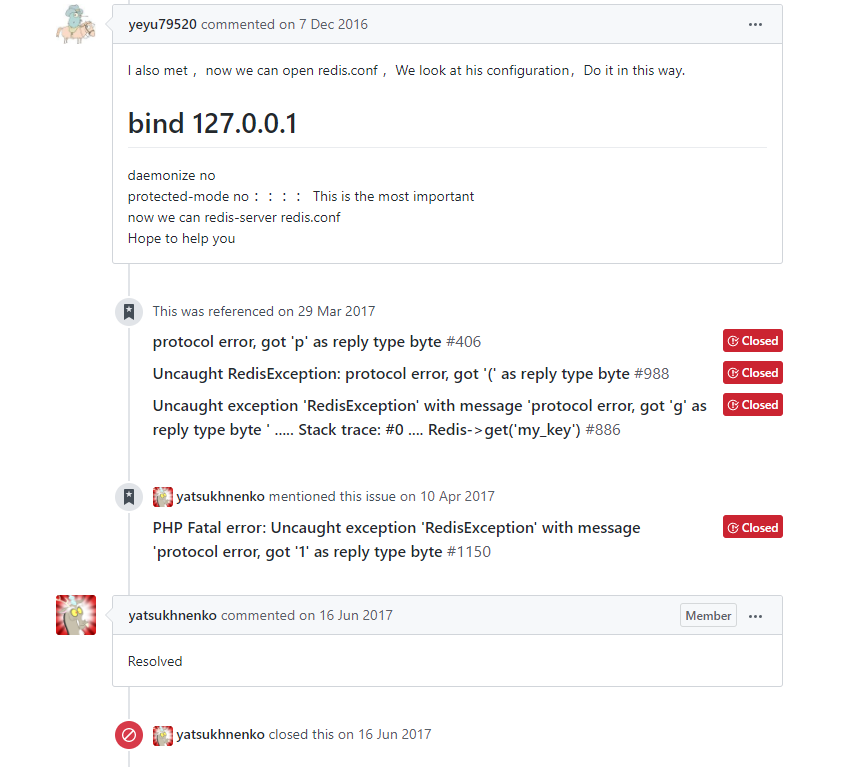
因为问题是出在客户端这边,为什么要修改redis服务器的一些配置甚至去升级呢?就感觉这个做法有点像头痛医脚。
柳暗花明
就在一筹莫展时候,我阅读了官网的协议文章
于是有了个推论会不会是底层的byte乱了。比如说我多了个CRLF或者少了个CRLF之类。于是做了些测试,的确验证了我的想法:
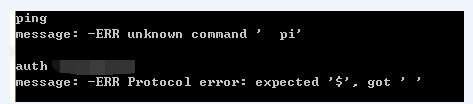
当出现protocol error后我自己写的客户端也被断掉了。虽然这个错误和monitor看到的错误并不一样,但看错误日志可以得出他们都属于protocol error这个大类型。
当redis抛出protocol error后会立刻关闭客户端的socket
上面的是我做出的一个结论。
继续测试
有了上面那个结论,我怎么去做测试数据来验证这点呢?因为协议的部分是底层实现不大可能多一个或者少一个关键字符。于是我想着自己做一些数据来验证这点。

程序逻辑大概是随机组合这些保留字符窜丢给redis,不过截至目前为止,我也没有试验出来断线。看样子就协议本身来说还是比较稳定的,只要底层协议按照官方的来,哪怕你输入了一些特殊字符, redis本身还是能顺利处理的。
到了这里,似乎又陷入了死胡同。。。
回到原点
既然错误是redis抛出来的,于是我回到了它的源码上面。很快就找到了一些端倪了:
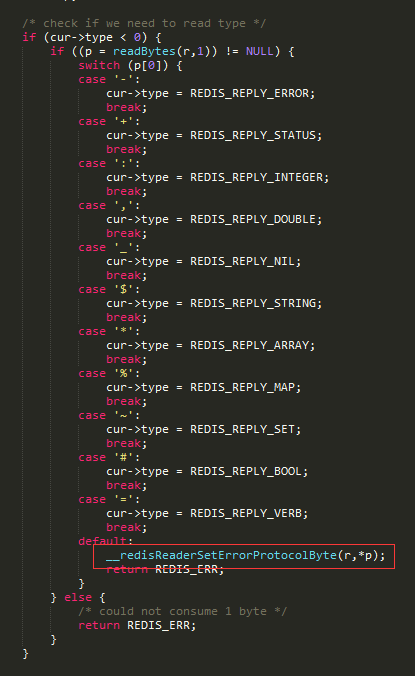
这段代码很明显是处理首字符的时候发现了未定义字符而抛错,进而redis认为连接的字符顺序错误了,从而导致了断线。并且有意思的是这段错误是来自hiredis而非redis服务器本身,另一个有意思的是老版本显然支持的协议字符要比上面的更少。
hiredis是redis作者写的一个客户端,可以推测使用的redis-cli命令应该是基于这个开发的,所以用monitor命令时候才会发现这个错误。看样子是回包时候,发现了数据错误。那么这个错误似乎和我们线上问题无关了。因为Failed to write明显是写的时候错误了。
暂时总结
- redis命令由于定义了一套自己的协议,第三方协议需要按照它来和redis交互。
- 出现protocol error必然会断线,所以一定要做好redis连接的保护。
- protocol error错误出现后,要关注后面的内容。有些事hiredis发出来的,有些是redis发出来的。
- 网上说得更改redis设置可以解决protocal错误明显是误导。都没有搞清楚这个错误是hiredis丢出来。
- 最后我还是觉得写入数据时候有概率写入魔鬼字符导致错误,这个需要后续跟进
暂时写这么多吧。